La plateforme Dataiku DSS propose aux équipes de professionnels des données de collaborer au sein d’un même environnement. Elle permet non seulement le traitement analytique des données, mais également le développement de nouvelles solutions. Découvrez tout ce que vous devez savoir sur Dataiku DSS.
Dataiku DSS est une plateforme de développement intégrée, destinée aux professionnels des données. Elle permet de convertir efficacement les données en prédictions. Cette plateforme logicielle se distingue par son approche collaborative. Les équipes de spécialistes au sein d’une entreprise peuvent l’utiliser pour explorer, développer et produire leurs propres produits data plus efficacement. La plateforme permet de préparer, mélanger et modéliser, d’automatiser le workflow, et de déployer la production.
Il s’agit d’un outil tout-en-un permettant de développer un projet de bout en bout, de la préparation au déploiement. Il permet de réunir les Data Scientists, les analystes et les opérateurs tous ensemble. Le logiciel permet d’améliorer une infrastructure existante qu’il s’agisse d’une Data Warehouse SQL ou d’un cluster Spark. C’est un environnement permettant la coexistence entre tous les standards de technologies Big Data et les différents langages.
À qui se destine Dataiku DSS ?
La plateforme DSS se destine aux Data Analysts, aux Data Scientists et aux Data Ops. Pour les analystes, elle se présente comme une interface visuelle interactive au sein de laquelle il est possible de pointer, cliquer, et développer en utilisant des langages comme SQL. Il est alors possible de confronter des données, modéliser, relancer les workflows, visualiser les résultats, et obtenir des insights sur demande. Ces fonctionnalités permettent aux Data Analysts d’augmenter leur efficacité.
Pour les Data Scientists et les développeurs, DSS permet de préparer et de modéliser les données en quelques secondes. Elle aide également à améliorer les bibliothèques ML comme scikitlearn, R, MLlib, ou H2O. Cet ensemble d’opportunités est offert par l’automatisation des tâches par le biais d’une interface entièrement personnalisable.
Pour les Data Ops, DSS retire l’inquiétude liée à l’utilisation de plateformes multi-technologiques. Elle permet de coordonner le développement et les opérations grâce à l’automatisation du workflow, la création de services web prédictifs, et la surveillance du statut des données et des modèles au quotidien.
À quoi sert Dataiku DSS ?
Les cas d’usage de DSS sont nombreux. La plateforme peut servir pour les analyses marketing, la détection de fraude, les graphiques analytiques, la gestion de données, la prévision de demande, les analyses spatiales, l’optimisation de valeur, la maintenance prédictive ou les analyses CRM.
Cette plateforme peut être utilisée dans de très nombreuses industries. Le secteur de la santé, le retail, les assurances, les banques, l’industrie pharmaceutique, le transport, les médias, l’automobile ou même le domaine du jeu vidéo peuvent profiter de ses nombreuses fonctionnalités.
Au sein de ces industries, DSS peut être utilisée par les divers départements tels que le marketing, la logistique, la R&D, la Business Intelligence, les laboratoires de données, les ventes ou les ressources humaines. Tous ces départements peuvent profiter de ses fonctions analytiques.
Fonctionnalités
Dataiku DSS repose sur plusieurs fonctionnalités utiles aux trois catégories de professionnels des données citées précédemment. Ces fonctionnalités peuvent être utilisées dans le cadre d’un développement collaboratif de produit Data ou pour l’analyse de données.
Connectivité

La plateforme DSS peut être connectée à une infrastructure existante, détecter les schémas et les formats, et les données n’ont pas besoin d’être déplacées pour être traitées. Au total, elle peut être connectée à 25 systèmes de stockage différents. Parmi ces systèmes, on dénombre des plateformes d’upload de fichiers comme Filesystem, FTP, HTTP, SSH, et SFTP. On compte également des SQL d’entreprise comme Oracle, MS SQL Server, mais aussi PostgreSQL et MySQL. Les SQL analytiques tes que Vertica, Greenplum, Redshift, Teradata, et Exadata sont également compatibles, au même titre que d’autres bases de données SQL. Les NoSQL tels que MongoDB, Cassandra et Elasticsearch sont eux aussi pris en charge. Le HDFS d’Hadoop, le Cloud S3 et bien d’autres encore viennent compléter ce tableau.
Cette connectivité peut être étendue grâce à divers plugins. Une API de connexion customisée est proposée pour pouvoir accéder à n’importe quelle donnée. Les projets Python customisés et les connecteurs peuvent être empaquetés pour être partagés avec une équipe ou une communauté. D’autres plugins et connecteurs sont directement implémentés par communauté d’utilisateurs.
Pour la détection de formats et de schémas de données, DSS effectue une prise en charge automatique. L’accès aux données est instantané, et ne nécessite pas l’écriture de paramètres de formatage fastidieux avant de consulter un ensemble de données. En quelques clics, même les membres de l’équipe dépourvus de compétences techniques peuvent accéder aux données.
Enfin, nul besoin de transférer les données pour les traiter. DSS se charge d’effectuer le traitement au sein d’infrastructures existantes de type SQL, Hadoop ou Spark.
Data Wrangling
Pour le Data Wrangling, DSS propose un nettoyage et un enrichissement interactif des données. L’utilisateur peut aisément accéder à plus de 80 processeurs visuels pour le wrangling code-free. Les transformations contextuelles sont automatiquement suggérées, et il est possible de procéder à des actions de masse sur les données.
Cette plateforme propose une interface simple pour interagir avec les données. Il suffit à l’utilisateur de filtrer et de chercher les données aussi facilement que sur Excel. Un simple clic permet d’accéder à des résumés statistiques de chaque élément. Le coloriage des valeurs de cellules aide à visualiser la qualité des éléments et la distribution de leurs valeurs.
Les processeurs intégrés sont regroupés dans une vaste bibliothèque. Ils permettent de traiter du texte, des dates, des zones géographiques, des URL, Email, JSON, et adresses IP, des codes postaux, des conversions de devises, des formules Excel et bien d’autres encore. Les macros et formules Python peuvent être utilisées pour le traitement personnalisé. L’utilisateur peut créer ses propres types personnalisés, spécifiques aux besoins de l’entreprise, pour vérifier la qualité des données et les traiter.
Machine Learning

La plateforme DSS propose un Machine Learning guidé pas à pas, permettant de nettoyer les données, de créer de nouvelles fonctionnalités, et de bâtir un modèle au sein d’un environnement unifié. Il est également possible de recevoir un feedback visuel instantané des performances de modèles. Les modèles peuvent être comparés et optimisés en utilisant différentes stratégies de validations croisées.
Le Machine Learning permet également de voir quels éléments ont le plus d’impact sur les prédictions avec une importance variable. Il est possible de comprendre rapidement les interactions complexes entre les éléments et d’analyser les coefficients. De même, les rapports visuels et statistiques automatisés aident à interpréter les clusters résultant d’un Machine Learning non supervisé.
Le code et l’interface visuelle permettent d’exploiter les dernières technologies de Machine Learning. L’interface permet de tirer profit des bibliothèques de Machine Learning Scikit-Learn, MLlib et XGboost. Le code peut être directement customisé sous Python et R pour un Machine Learning personnalisé avancé. N’importe quelle bibliothèque externe de Machine Learning est accessible par l’intermédiaire de diverses API de code comme H2O, Dato ou Skytree.
En outre, Dataiku DSS est entièrement prêt pour la production. Dès qu’un modèle est développé, il est instantanément possible de l’utiliser pour le batch scoring au sein du data workflow. Il peut ensuite être déployé comme service de prédiction en temps réel, et son temps de vie peut être géré en sauvegardant les versions précédentes d’un modèle et en effectuant un rollback vers une version sécurisée en un seul clic. De même, une boucle de feedback permet de gérer les performances du modèle.
Data Mining

Les insights visuels sont immédiatement fournis par DSS. Les données peuvent être glissées et déposées pour développer des graphiques en vue d’une exploration des données. Les 25 formats intégrés de classement permettent de comprendre les données en un clin d’œil. De même, DSS optimise les performances en dressant les classements automatiquement sur l’infrastructure SQL ou Impala existante.
La plateforme regroupe également des notebooks Python, R et SQL interactifs. Ces notebooks permettent la découverte de données. En vue d’une coloration et d’une complétion du code, Jupyter est intégré. L’utilisateur peut également créer ses propres rapports personnalisés et les mettre à jour.
Enfin, il est possible de miner à l’échelle grâce à l’intégration Spark et Hadoop dans le cluster. Spark est pleinement pris en charge, avec le support de PySpark, SparkR et SparkSQL. C’est également le cas des moteurs Hadoop Hive, Impala et Pig.
Data Visualization

La Data Visualization est assurée par 25 formats intégrés de classements et graphiques. L’utilisateur peut utiliser des histogrammes, des cartes, des heatmaps, des boxplots et bien plus encore. Les visualisations peuvent être mises en place très facilement, et les données peuvent être explorées à l’aide d’un système intuitif de glisser-déposer.
Les codeurs peuvent créer leurs propres visualizations basées sur le web en utilisant les meilleures bibliothèques Javascript comme d3.js, Leaflet, et plot.ly. Des applications web avancées peuvent être créées à l’aide du backend Python. Toutes ces applications sont sécurisées grâce à une gestion des clés API.
Les tableaux de bord et insights peuvent être partagés par le biais de charts intégrés, d’applications personnalisées, de notebooks et rapports Python et R mis à jour, et d’accès à des ensembles de données téléchargeables.
Data Workflow

Les Data Workflows peuvent être visualisés et relancés facilement. Toutes les étapes des projets Data peuvent être consultées pour revoir chaque manipulation effectuée. Un moteur de reconstruction permet de limiter les calculs aux ensembles de données nécessaires afin de relancer efficacement le workflow. De même, le recomputing peut être limité aux parties des ensembles de données qui ne sont pas mises à jour grâce à un fin partitionnement.
Les scénarios d’automation sont assurés par des outils d’orchestration intégrés permettant la gestion de tâches, le triggering et les notifications. Ils peuvent être implémentés directement au sein de l’interface ou en utilisant l’API de scénario DSS Python. De même ces scénarios sont aisément intégrés à l’aide d’un orchestrateur externe grâce à DSS REST API. Le workflow peut être lancé automatiquement lors de changement de données ou en se basant sur des conditions personnalisées.
Pour la surveillance de données et de traitements de données, le tableau de bord DSS aide à s’assurer que le déploiement se déroule correctement. Les polices de validation de données automatiques peuvent être implémentées, et les données critiques ou les mesures de modèles peuvent être vérifiées à chaque lancement. L’évolution des modèles peut être suivie et visualisée au fil du temps.
Scoring en temps réel

Le passage du design à la production se fait sans transition. En quelques clics, l’utilisateur peut déployer un modèle vers la production pour recevoir des prédictions en temps réel grâce à la REST API. Le nettoyage, l’enrichissement et le prétraitement des données, au même titre que les modèles de scoring, accélèrent fortement le déploiement. Les modèles déployés sont versionnés, permettant un rollback à tout moment.
La scalabilité et la disponibilité sont assurées grâce au queuing, au parallélisme et à l’équilibrage de chargement permettant de gérer de larges quantités de prédictions en temps réel. De multiples nœuds d’API de scoring peuvent être lancés pour une disponibilité complète.
Enfin, le model drift peut être évité grâce à une boucle de feedback. Plusieurs versions du même modèle peuvent être lancées en même temps pour un test A/B automatisé. Les changements de données peuvent être surveillés au fil du temps. Il est possible d’accéder aux à l’historique des requêtes de logs et aux prédictions à n’importe quel moment pour vérifier que la performance de modèle reste stable au fil du temps.
Collaboration

DSS est initialement conçu pour le travail d’équipe, et le partage de connaissances ainsi que la collaboration sont facilités par différentes fonctionnalités. Il est possible d’ajouter de la documentation, des informations et des commentaires sur chaque objet DSS. Des listes Todo intégrées permettent une collaboration immédiate.
La gestion de changement est assurée par le versioning et l’enregistrement de chaque action au sein de dossiers Git intégrés. Chaque action peut être suivie dans la timeline au sein de l’interface, et il est facile d’effectuer un rollback vers une version précédente.
Des tableaux de bord dédiés aident les gestionnaires de projet à garder un œil sur l’activité de leur équipe. Ces tableaux sont séparés entre les projets actifs et inactifs, et la progression et les actions de l’équipe.
Déploiement
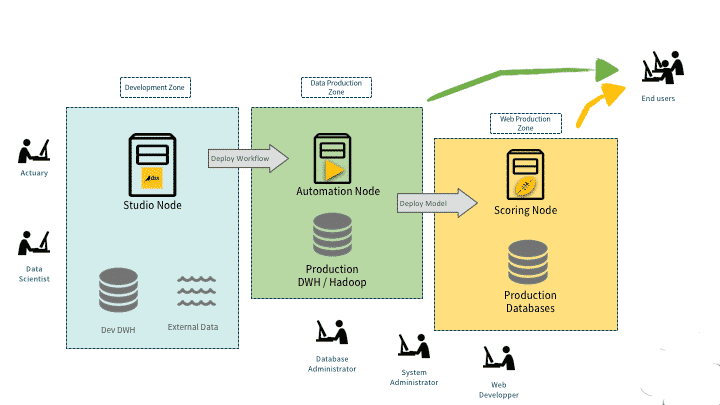
Pour le déploiement du workflow, DSS permet d’empaqueter le workflow en incluant les données et les modèles. Il est également possible d’installer des instances d’automatisation DSS pour lancer des workflows exportés. Les modèles de déploiement sont fournis au sein d’une seule interface utilisateur, du développement au test et de la préproduction à la production.
Toutes les versions des workflows peuvent être facilement gérées, passées en revue et les nouvelles versions peuvent être directement activées. En cas de problème, DSS permet d’effectuer un rollback et de s’assurer qu’un workflow reste consistant. Les déploiements sont automatisées au sein d’une stratégie de production plus large, et tous les scénarios de données peuvent être lancés à l’aide de la REST API.
Entreprise
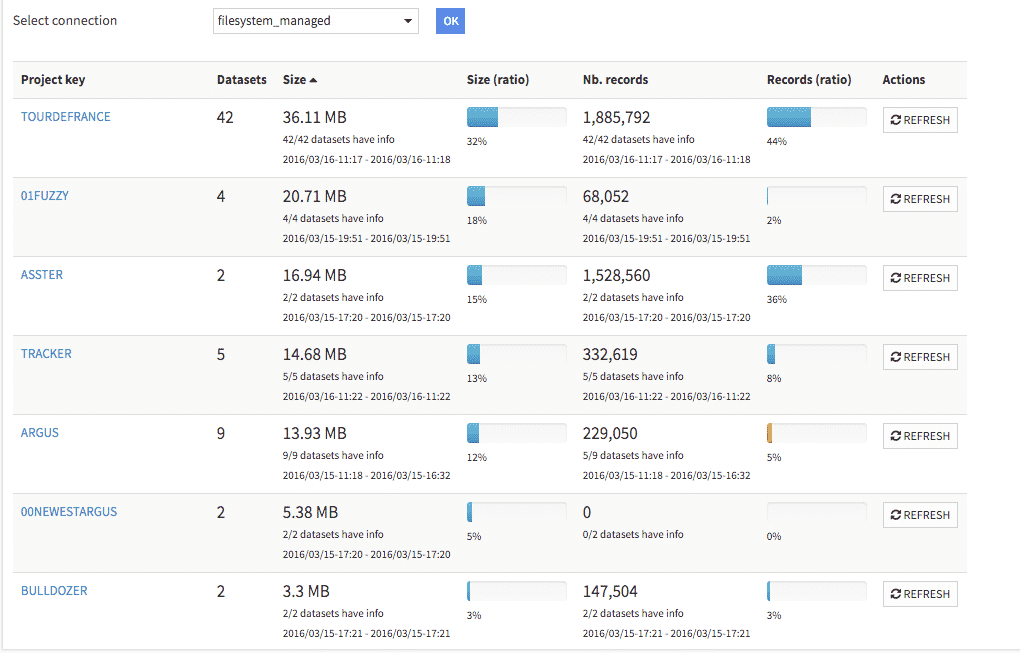
Pour la gouvernance des données, toutes les tâches de données peuvent être organisées en projets clairement identifiés. Les actions et les ensembles de données sont documentés. Les données, les commentaires, les éléments et les modèles peuvent être cherchés au sein d’un catalogue centralisé.
La sécurité est garantie par plusieurs fonctionnalités. Les données sont sécurisées à l’aide d’un système de permissions, toutes les activités peuvent être surveillées à travers des tableaux de bords dédiés, et les directory services peuvent être intégrés à Hadoop (ldap ou kerberos).
Pour une surveillance avancée, des tableaux de bord dédiés permettent de surveiller l’activité DSS, la taille et la localisation des ensembles de données, et l’activité du cluster et des tâches DB. Les chefs d’équipe peuvent ainsi suivre l’avancée des projets en permanence.
Vous savez tout sur la plateforme analytique Dataiku DSS. Si vous estimez qu’elle répond à vos besoins, n’hésitez pas à vous rendre sur le site officiel de Dataiku pour demander une estimation des tarifs.
Cet article Tout savoir sur Dataiku, la plateforme de développement analytique collaborative a été publié sur LeBigData.fr.